介绍
Raft 是一种用于分布式系统的共识算法,它的设计目标是让分布式一致性更容易理解和实现。
核心思想
Raft 通过选举一个领导者(Leader)来简化共识过程。所有的数据修改都必须先提交到 Leader,然后由 Leader 负责将日志复制到其他节点(Followers)。这种方式比 Paxos 等算法更直观。
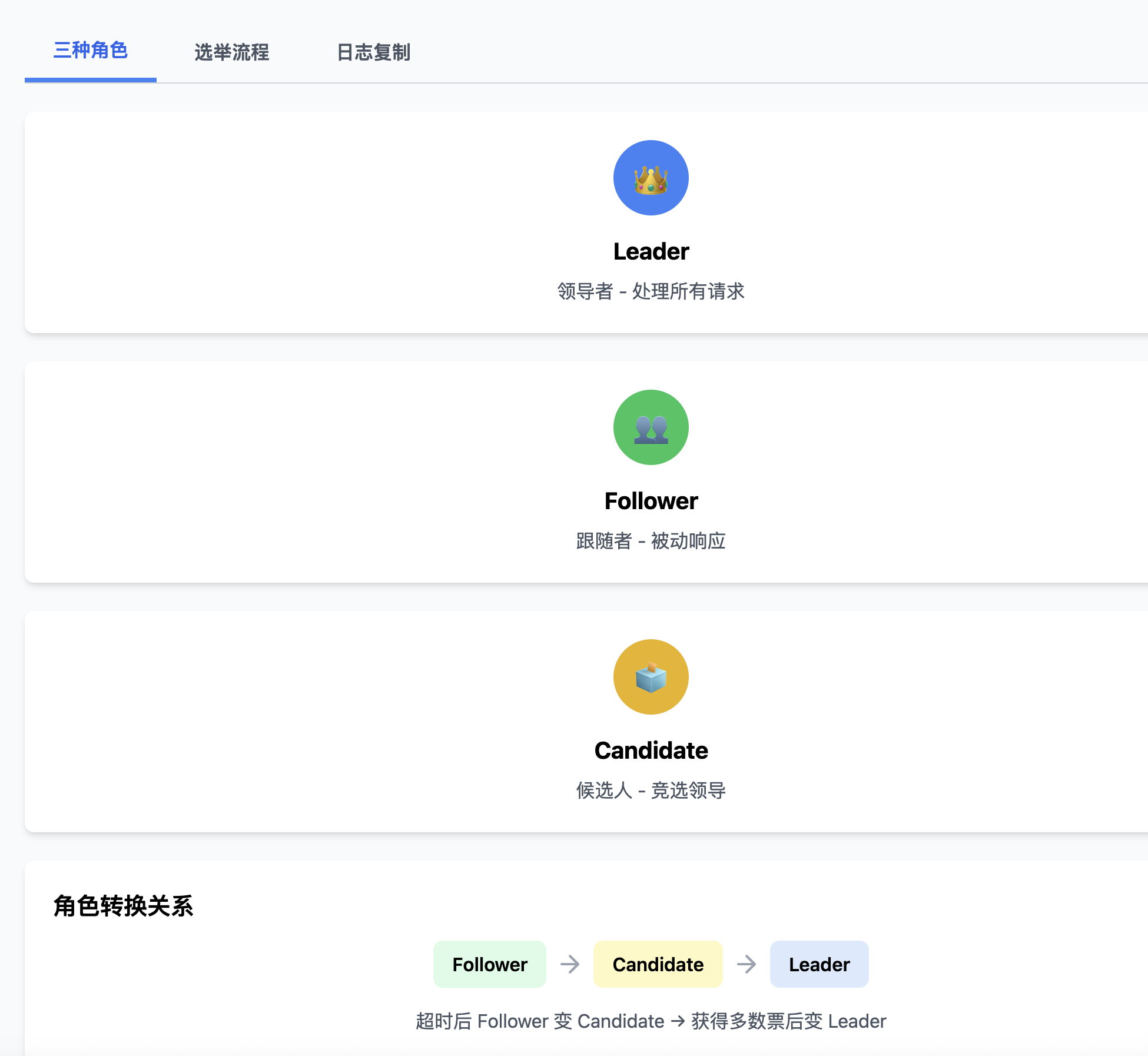
三种角色
系统中的每个节点都处于以下三种状态之一:Leader 负责处理所有客户端请求并管理日志复制,Follower 是被动的,只响应 Leader 和 Candidate 的请求,Candidate 是在选举新 Leader 时的临时状态。
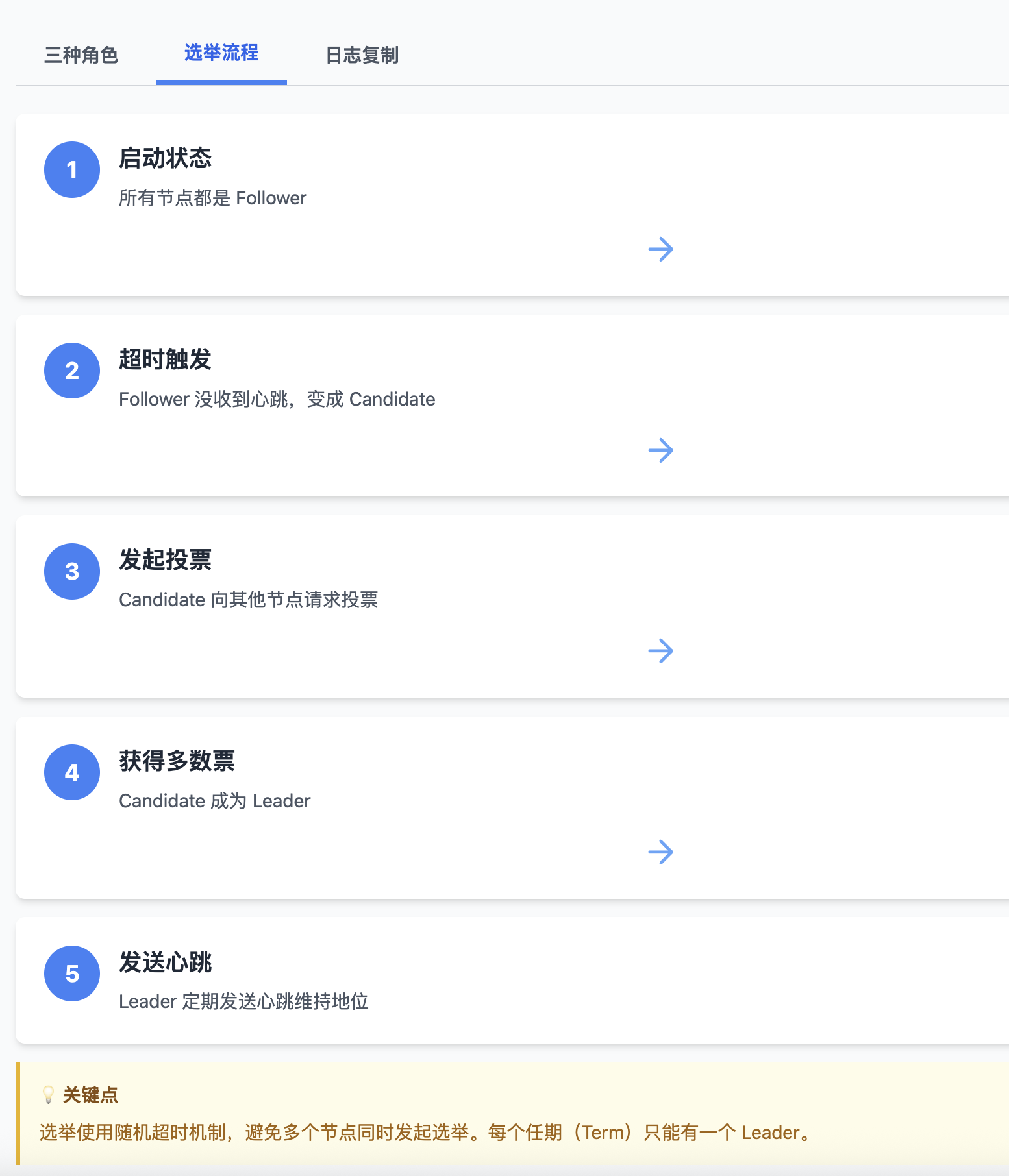
工作流程
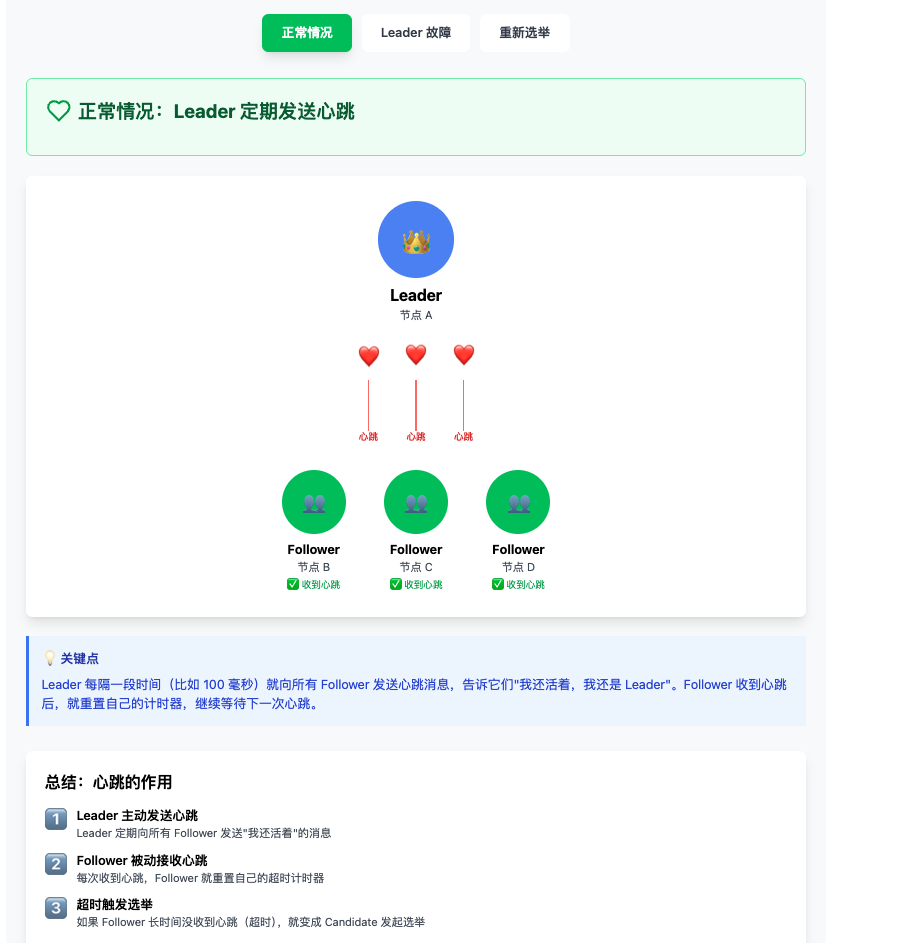
系统启动时,所有节点都是 Follower。如果 Follower 在一定时间内没有收到 Leader 的心跳,它会转变为 Candidate 并发起选举。Candidate 向其他节点请求投票,如果获得多数票就成为 Leader。Leader 会定期向所有 Follower 发送心跳来维持其地位。
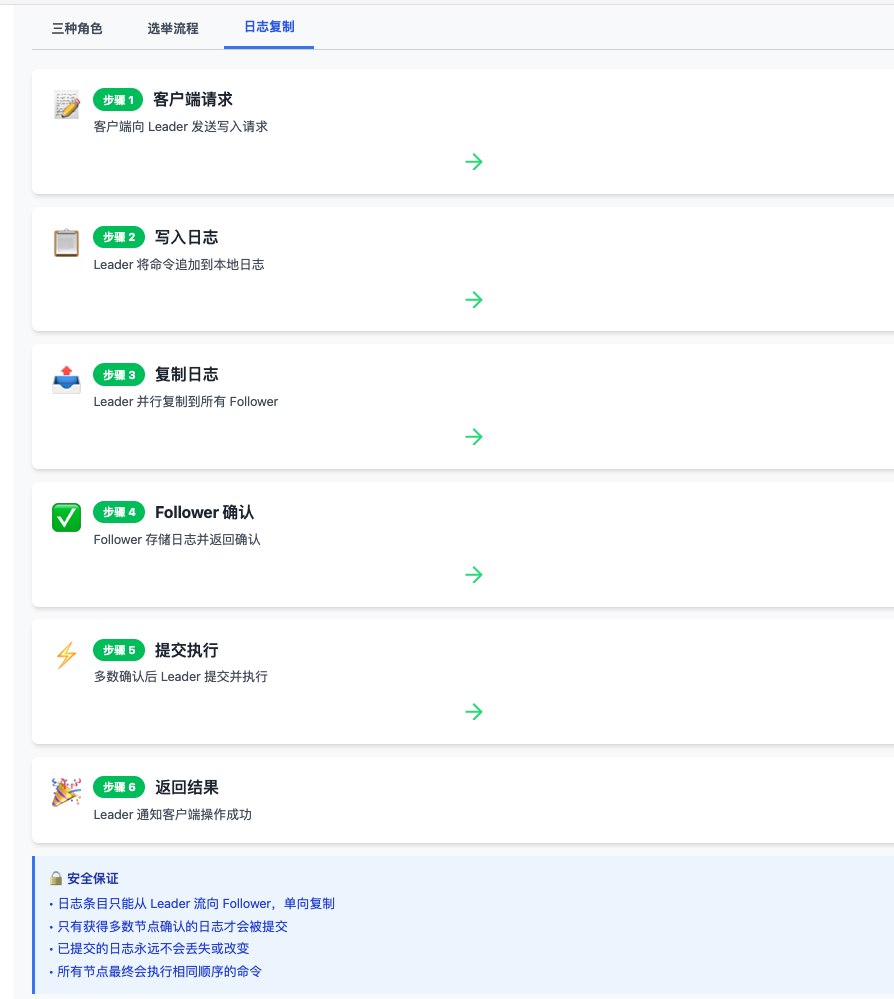
日志复制
当客户端向 Leader 发送请求时,Leader 将操作追加到自己的日志中,然后并行地将这个日志条目复制到所有 Follower。一旦多数节点确认收到并存储了该日志,Leader 就会提交这个条目并返回结果给客户端。
安全保证
Raft 保证已经提交的日志不会丢失,并且所有节点最终会按相同的顺序执行相同的命令。即使发生网络分区或节点故障,系统也能保持一致性。选举时会确保拥有最新日志的节点才能当选为 Leader。
Raft 被广泛应用于 etcd、Consul 等分布式系统中,它的可理解性使得工程师更容易正确实现和调试分布式一致性系统。
Raft 协议可视化流程图
三种角色
选举流程
日志复制
心跳机制详解
正常情况
Leader故障
![image.png]
(http://blog.go2live.cn/static/upload/202510/269ikhfcalza.png)
重新选举
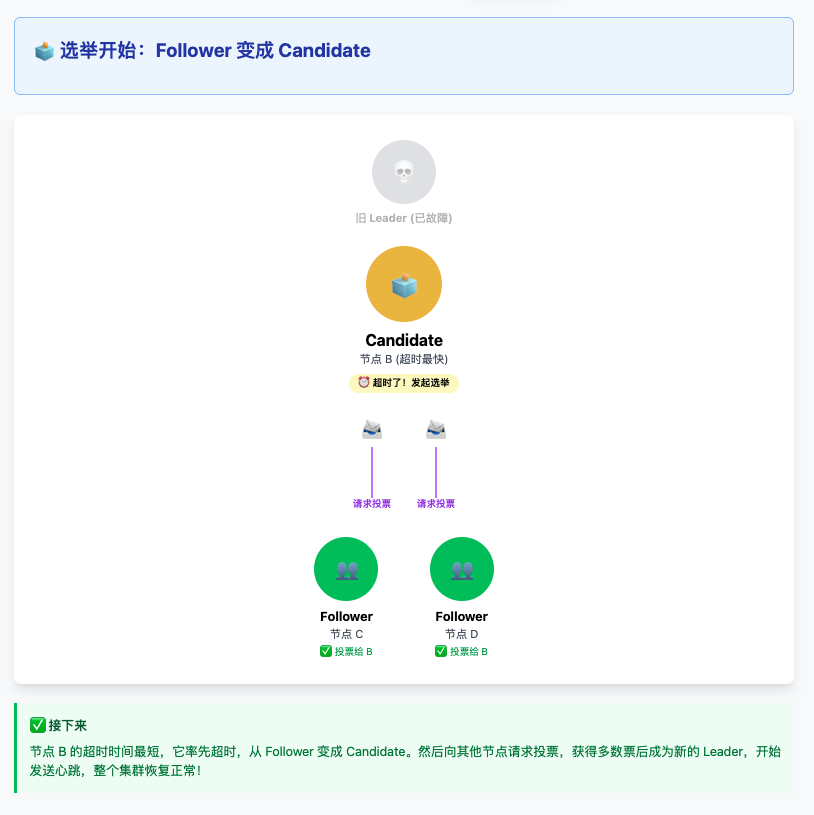
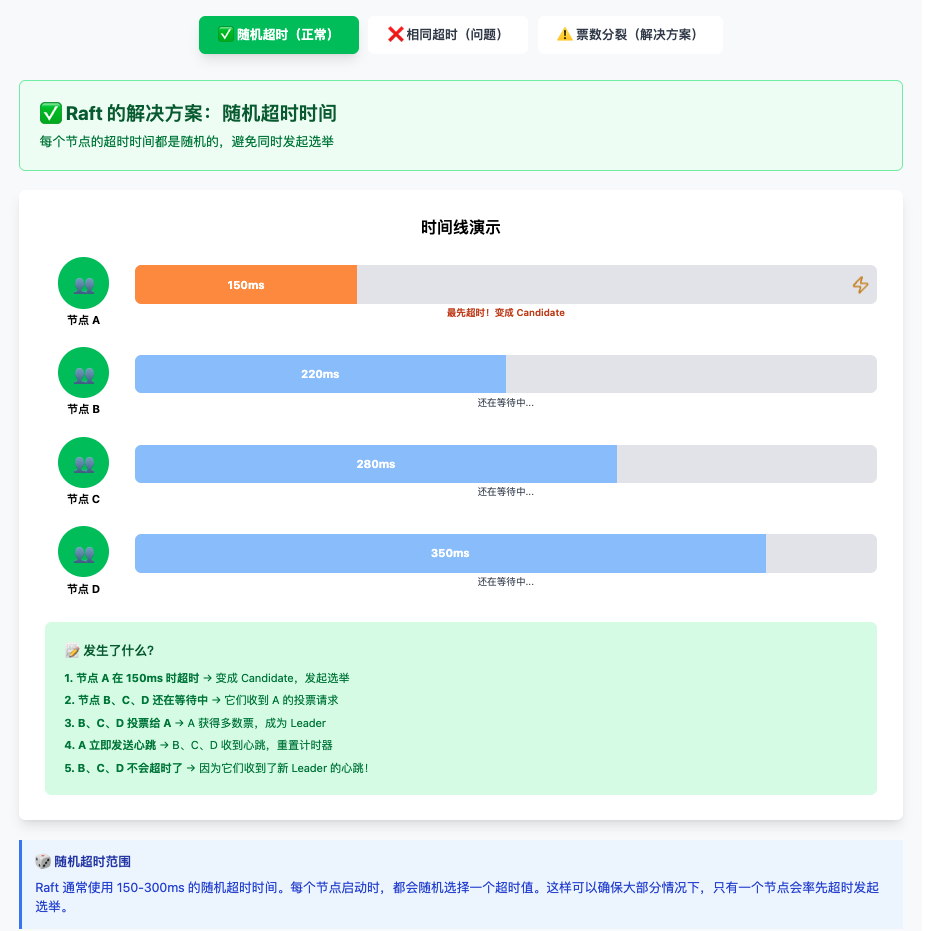
Raft 如何避免同时选举?
随机超时
相同超时(问题)

票数分裂
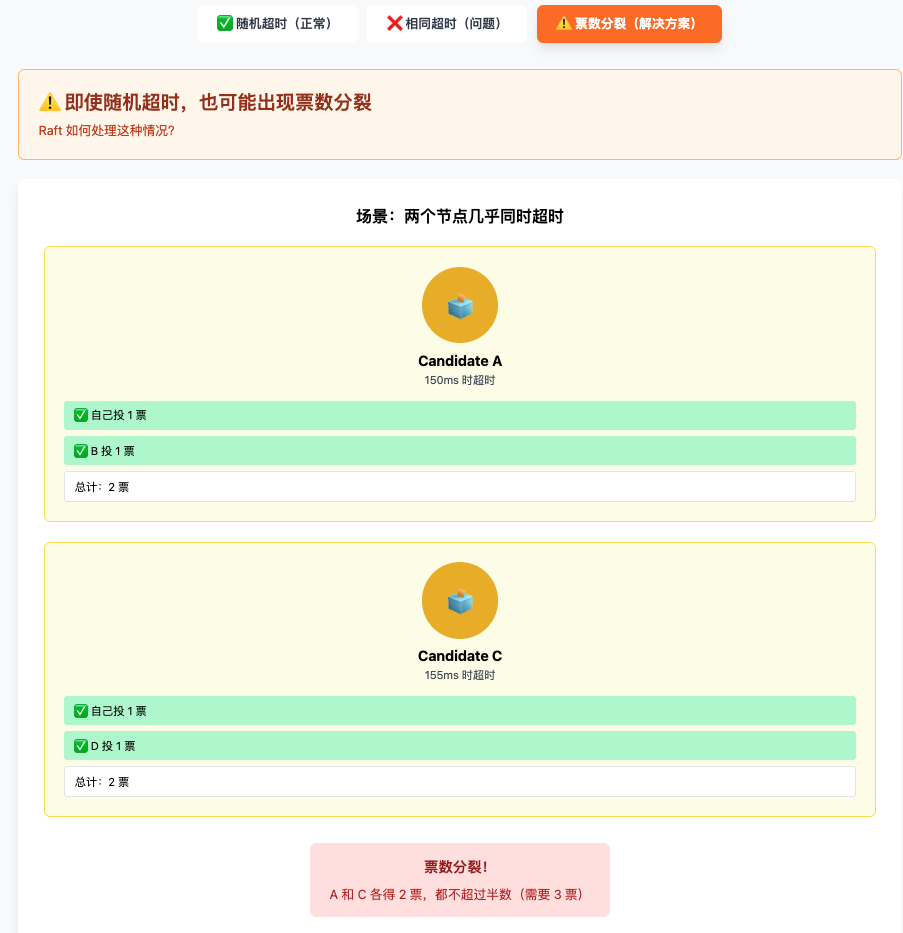
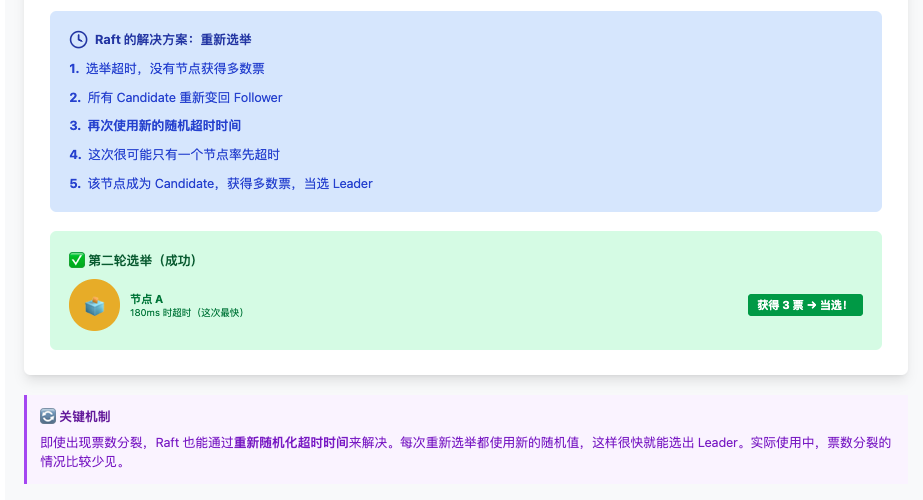
Raft 到底解决了什么问题?
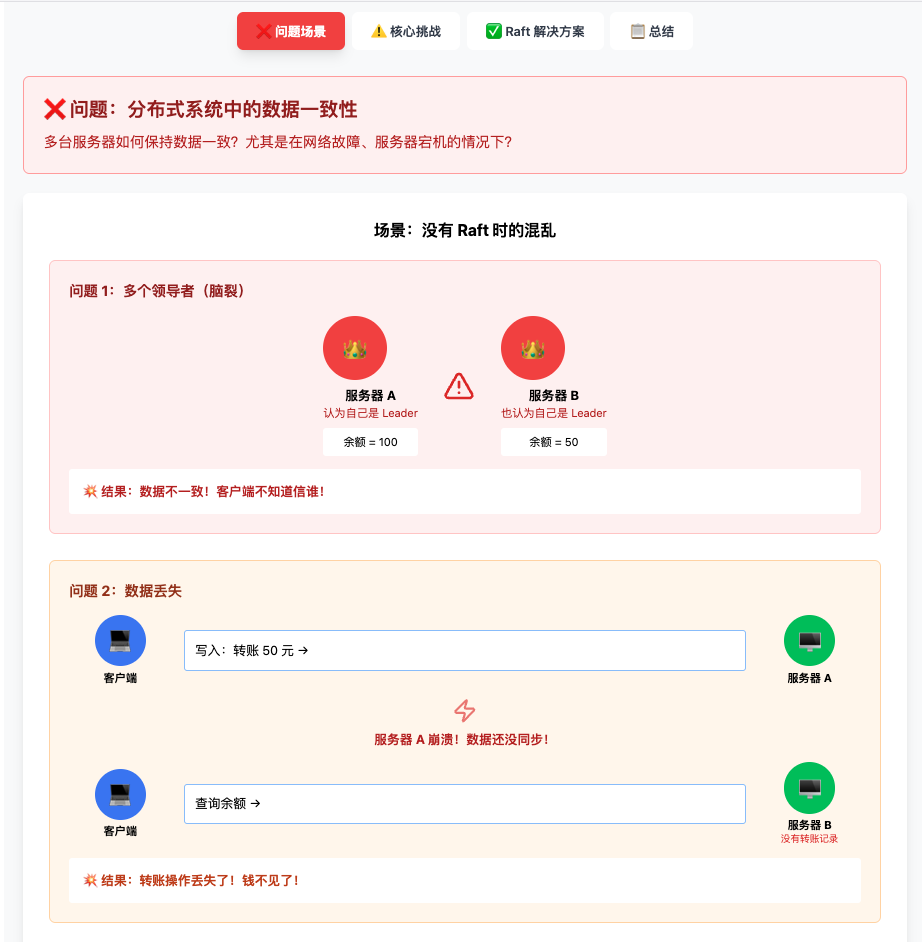
分布式系统中的数据一致性难题
问题场景

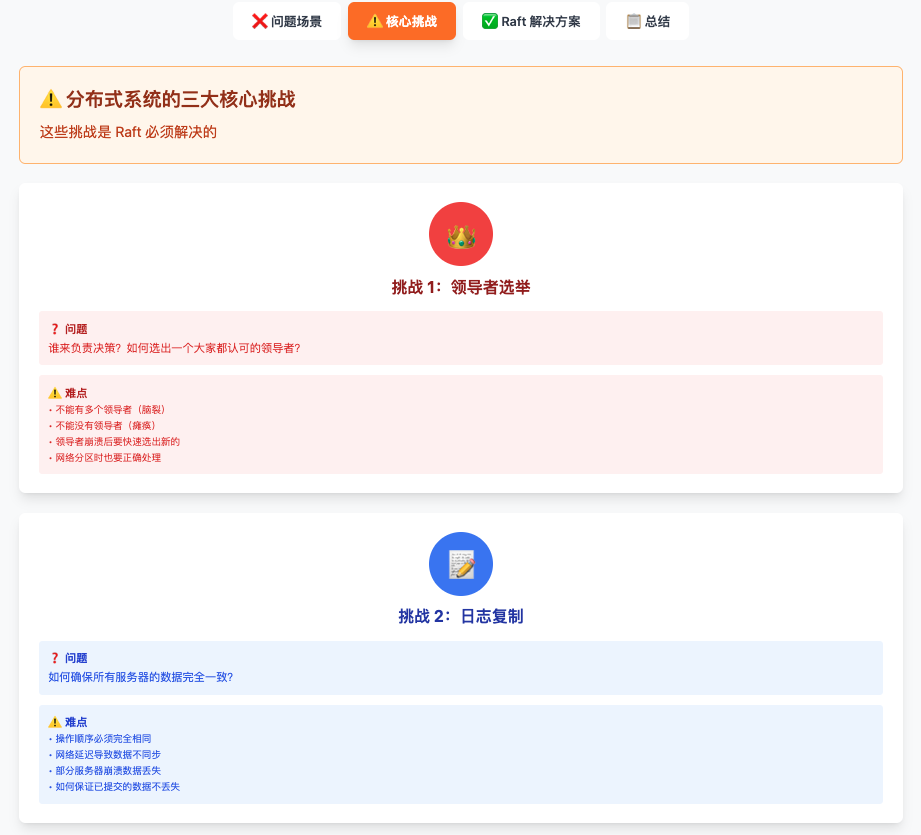
核心挑战

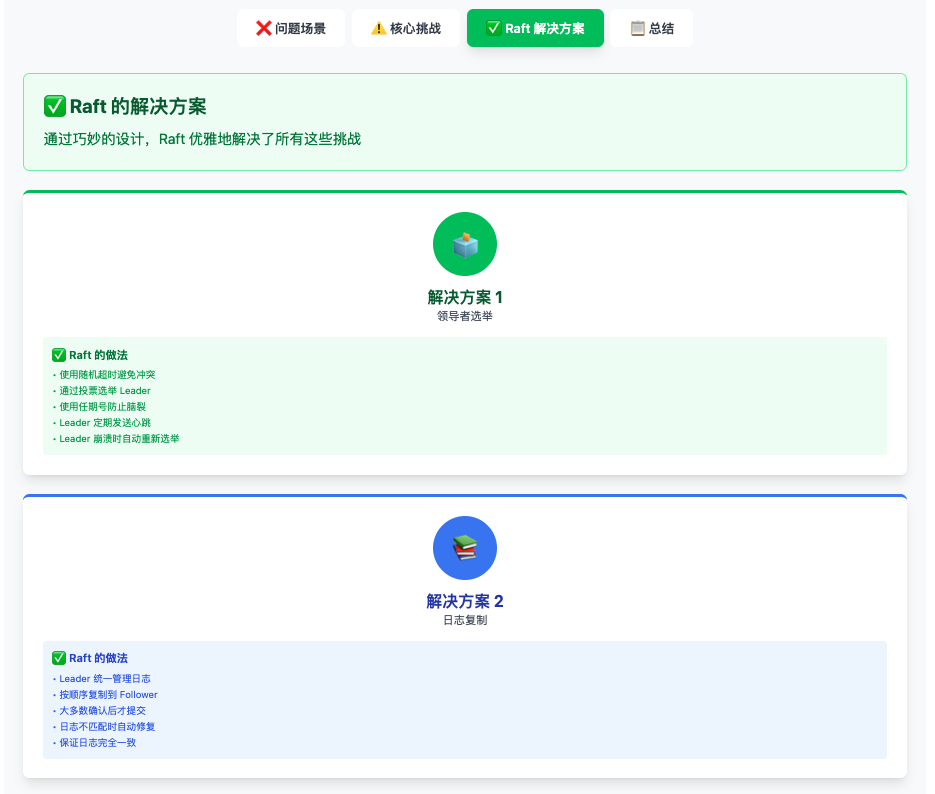
Raft 解决方案

总结

