Day 4:从 SQL-only 到 Redis + Lua 的抽奖优化实战
本文记录今天将抽奖核心从“纯数据库事务”升级为“Redis + Lua 原子扣减 + 异步落库”的过程、优化点、踩坑与结果。
目标与背景
- 目标:在保证功能正确与可观测的前提下,提高单机并发与整体吞吐,缓解数据库热点与锁竞争。
- 背景:V1 方案所有请求走 PostgreSQL 事务,存在连接/锁瓶颈;V2 引入 Redis 作为热点写入层与限流去重层。
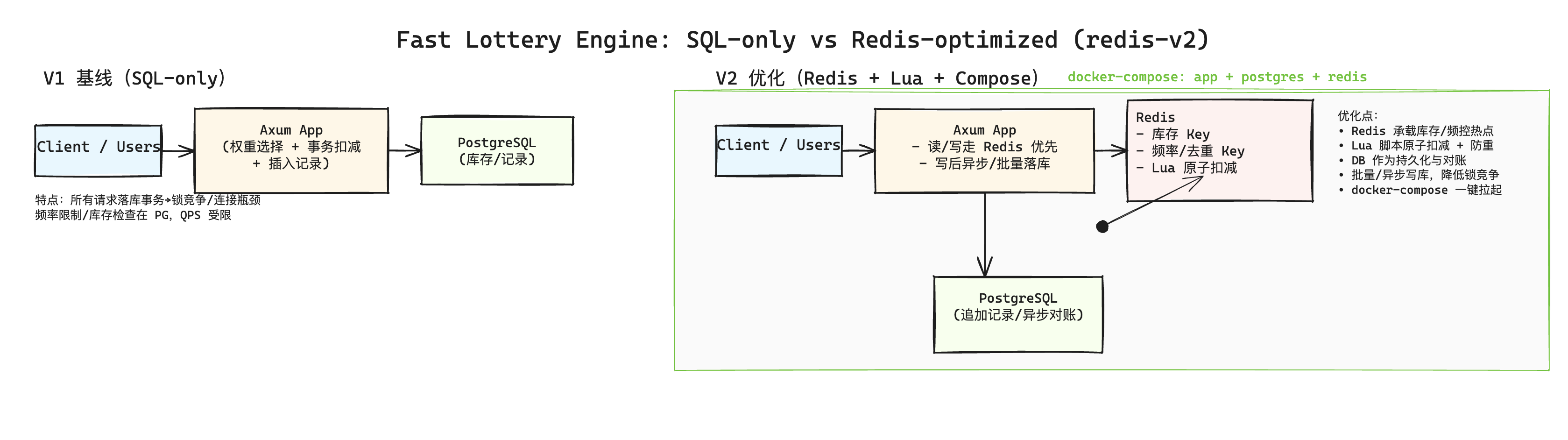
架构与实现
- docker 多阶段构建:
- builder(rust:1)编译产物;runtime(debian-slim)只运行三进制:
fast-lottery-engine/migrate/db_prepare。 - entrypoint 顺序:migrate → db_prepare → 启动服务。
- builder(rust:1)编译产物;runtime(debian-slim)只运行三进制:
- 环境配置:本机
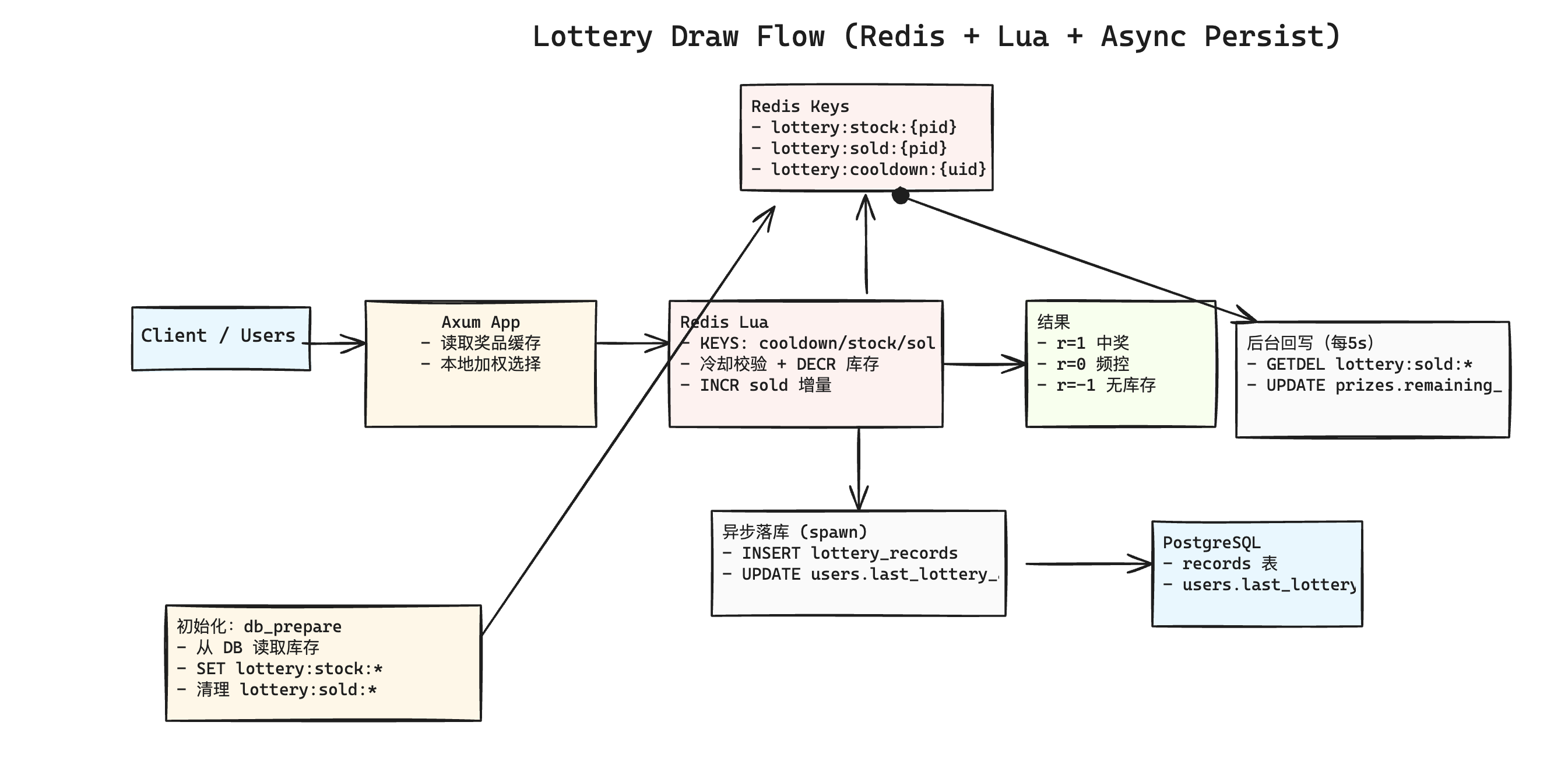
.env与容器.docker.env分离;compose 使用env_file: .docker.env,端口映射 app 18080、PG 15432、Redis 16379。 - 抽奖路径(新):
- 读取“启用奖品”的权重信息(内存缓存,定时刷新)。
- 本地加权随机选中候选奖品。
- 调用 Redis Lua 原子脚本:
lottery:cooldown:{uid}冷却键(限频)。lottery:stock:{prize_id}库存键,DECR。lottery:sold:{prize_id}增量键,INCR(用于回写 DB)。
- 结果异步写入
lottery_records,并更新users.last_lottery_at。
- 数据同步:
- 初始化:
db_prepare从 DB 读取各奖品remaining_count,写入lottery:stock:*,并清理lottery:sold:*。 - 回写:后台任务每 5s 执行一次
GETDEL lottery:sold:*,将增量安全扣减回 PostgreSQL(避免竞态)。
- 初始化:
性能优化点
- 全局 Redis 连接管理器:使用
OnceCell复用连接,避免每请求建连导致的 QPS 下降。 - 内存奖品缓存:每 800ms 刷新一次启用奖品与权重,抽奖不再每次查询 DB。
- 异步落库:抽奖记录与用户最近时间通过
tokio::spawn后台写入,减少请求临界路径阻塞。 - 统计输出改为毫秒,便于研判尾延迟。
基准结果(本机环境)
- 纯数据库(参考历史):约 4k QPS。
- 初版 Redis(未复用连接、无缓存):约 2.0–2.6k QPS。
- 最终方案(连接复用 + 内存缓存 + 异步落库):
- ops=10000, conc=256, time≈296ms, QPS≈33,780
- 延迟(ms):avg≈6.36, p50≈5.23, p95≈11.57, p99≈33.24
说明:数据受本机硬件、网络与运行时状态影响,仅供相对比较。
踩过的坑与修复
- 容器启动 cargo not found:使用 rust 基础镜像运行源码会因 PATH/环境不同导致找不到 cargo;改为多阶段构建,仅运行编译产物。
- compose 健康检查库名不一致:
fast_lottery→lottery,否则pg_isready失败。 - Redis Lua 调用需要
&mut连接:invoke_async需可变连接;初版误传&ConnectionManager导致编译错误。 - API 变更:
get_tokio_connection_manager已废弃,改用get_connection_manager。 - OnceCell 使用:
get_or_try_init需要|| async { ... }的闭包写法。 - 测试环境变量:
TEST_PG_URL未加载导致 nextest 失败;在各测试用例顶部显式dotenvy::dotenv()。 db_prepare重复/过期代码:清理重复的 Redis 种入逻辑与漏掉的分号。- 基准单位:输出从
us改为ms,更易阅读。
一致性与限制
- 进程内缓存存在一致性窗口(<1s),仅用于权重读取,不承载库存;库存仍以 Redis 为准。
- 增量回写采用
GETDEL,避免与扣减并发写入冲突;应用异常退出时,增量键仍保留,重启后继续回写。 - 当前仍为单实例 Redis 部署示例,未引入分布式分片与有序事件流,适合演示与单机/小规模压测。
技术决策与问答摘录
- 问:宿主机开发端口如何安排?EXPOSE 还是 ports?
- 决策:宿主机访问必须
ports映射;我们将 app/PG/Redis 改为非常用端口(18080/15432/16379)以避免冲突。
- 决策:宿主机访问必须
- 问:本地与容器环境变量如何隔离?
- 决策:采用
.env(本机)与.docker.env(容器)分离,compose 使用env_file: .docker.env;.docker.env忽略提交,并提供.docker.env.example。
- 决策:采用
- 问:app 容器应否编译源码?
- 决策:否。采用多阶段构建,仅运行已编译二进制,启动更快、镜像更小且避免 cargo/路径问题。
- 问:Redis 如何初始化库存?
- 决策:在
db_prepare中读取 DB 的remaining_count,写入lottery:stock:{prize_id},并清理lottery:sold:{prize_id};entrypoint 保证顺序:migrate → prepare → serve。
- 决策:在
- 问:扣减后如何同步回 DB?为什么不直接用
lottery:stock:{prize_id}覆盖 DB?- 决策:使用增量键
lottery:sold:{prize_id}+ 定时GETDEL回写,避免“读 stock 与并发 DECR 冲突”的竞态覆盖;绝对量覆盖需暂停写或引入版本/CAS,复杂且风险大。
- 决策:使用增量键
- 问:频控在哪里做?
- 决策:在 Lua 中设置/校验
lottery:cooldown:{uid},中奖与否都设置,避免重试风暴。
- 决策:在 Lua 中设置/校验
- 问:为什么加内存缓存?一致性如何?
- 决策:缓存仅存权重与可用列表,降低 DB 压力;缓存刷新周期 800ms,库存仍以 Redis 为准。若需更强一致性,后续改为“权重表存 Redis + 版本热更新”。
- 问:测试为何失败?
- 决策:nextest 默认不加载
.env,在各测试中显式dotenvy::dotenv();并要求设置TEST_PG_URL。
- 决策:nextest 默认不加载
- 问:基准延迟单位可读性?
- 决策:输出从 us 改为 ms,便于观察 p95/p99。
为什么更快
- 热路径不落库:库存扣减与频控都在 Redis 用 Lua 原子完成,避免 DB 事务锁与连接瓶颈。
- 连接与读优化:复用全局 Redis 连接;奖品权重用内存快照,避免每次 draw 查询 DB。
- 写入解耦:抽奖记录与用户时间异步写库,库存回写走增量批处理(GETDEL),显著缩短请求临界路径。
- 结果:从 ~4k QPS 提升到 ~33.8k QPS,尾延迟(p99)稳定在几十毫秒级。
后续演进方向(暂不实施)
- 全量权重/别名表存 Redis,Lua 内完成“抽签+扣减+限频”,应用节点无本地缓存。
- 配置热更新:版本键 + Pub/Sub(或 Keyspace 通知)广播,各节点热重载。
- 结果落库改为事件流(Redis Stream/Kafka),消费者落表与对账,支持重放。
- Redis Cluster 分片(按活动或 prize_id),进一步提升水平扩展能力。
最终压测结果:QPS≈33.8k,avg≈6.36ms,p99≈33.24ms;后续若需要,可以继续按“全 Redis 原子化 + 流式落库”的方向演进以追求更高吞吐与更强一致性。