高并发系统的设计本质上是一场资源与需求之间的博弈。当系统面临流量洪峰时,我们需要的不是单一的技术方案,而是一套系统性的思维框架。这个框架的核心可以概括为一句话:分层加缓存。但这句话背后,隐藏着无数需要权衡的技术决策。
性能的本质认知
在动手优化之前,我们必须建立一个清晰的性能认知体系。从硬件层面看,时间消耗的量级差异是惊人的:
硬件层面时间消耗(对数坐标)
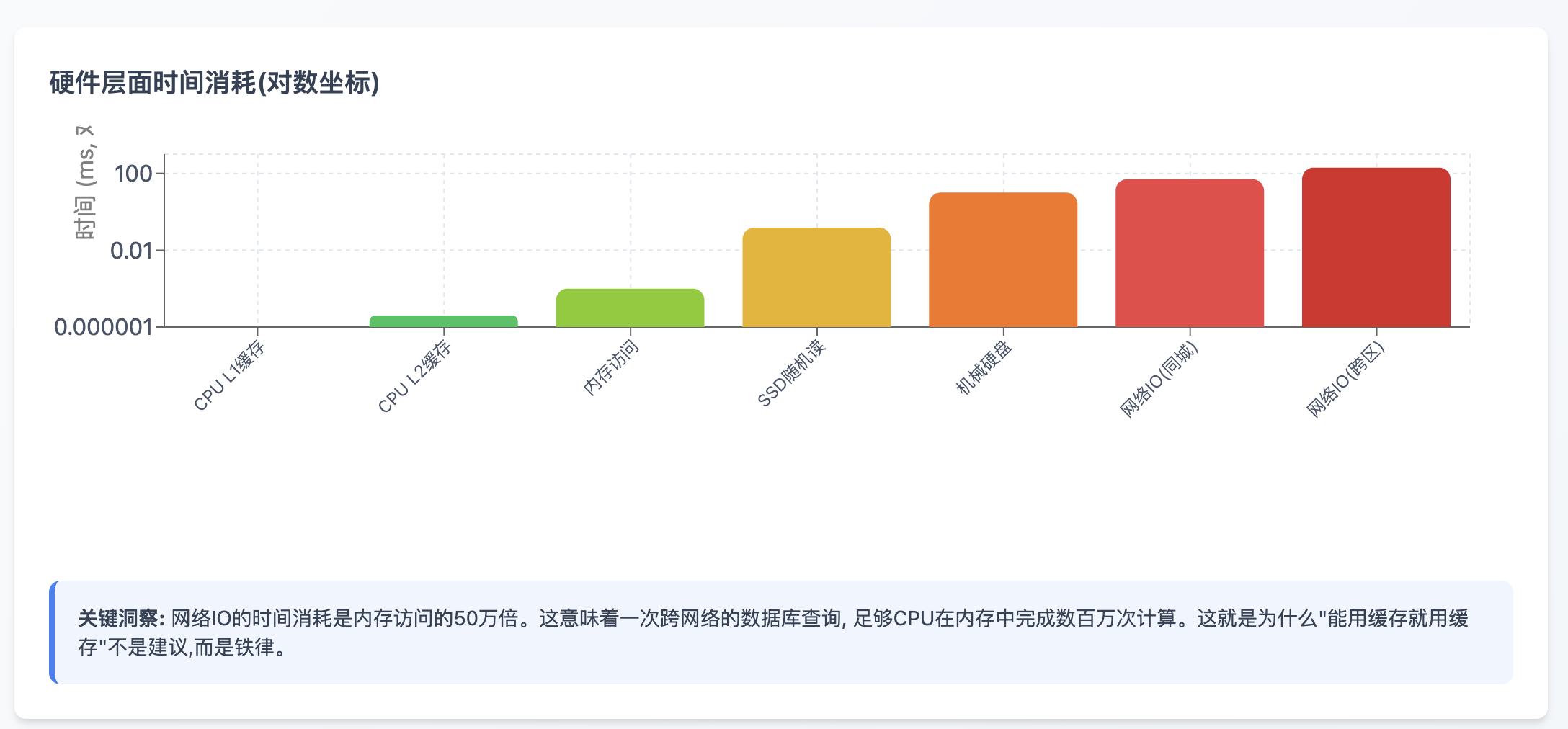
网络调用的时间,足够CPU执行数千万次指令。这个数量级差异告诉我们一个残酷的事实:在分布式系统中,网络永远是最大的敌人。
业务场景性能对比

落到实际业务场景中,这个性能阶梯体现得更加直观。让我用一个真实案例说明:某电商平台的商品详情页,最初直接查询MySQL,每次请求需要联表查询商品基础信息、库存、价格、评价等多张表,单次请求耗时200-300ms,系统只能支撑每秒500次访问。引入Redis缓存后,90%的请求直接命中缓存,响应时间降到5ms以内,同样的硬件资源支撑了每秒5万次访问,性能提升了100倍。这不是Redis比MySQL更优秀,而是内存访问比磁盘访问快1000倍的物理规律在起作用。
分层架构的实践智慧
分层加缓存不是简单地堆砌技术组件,而是根据数据的访问特征和变化频率进行精心设计:
多层存储架构设计
访问频率递减,存储容量递增,成本递减
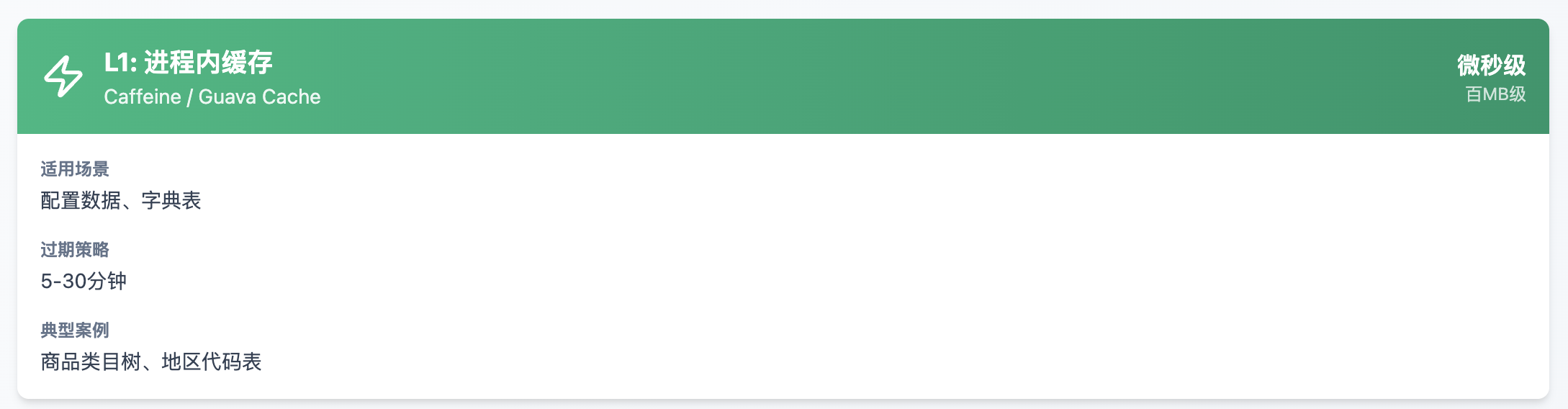
L1: 进程内缓存
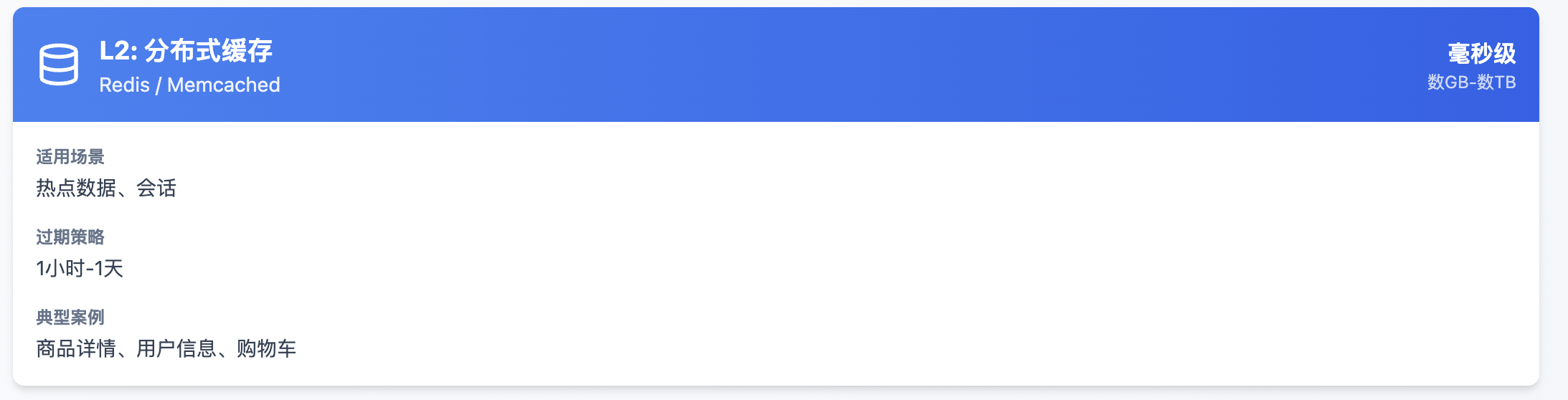
L2: 分布式缓存
L3: 非事务存储

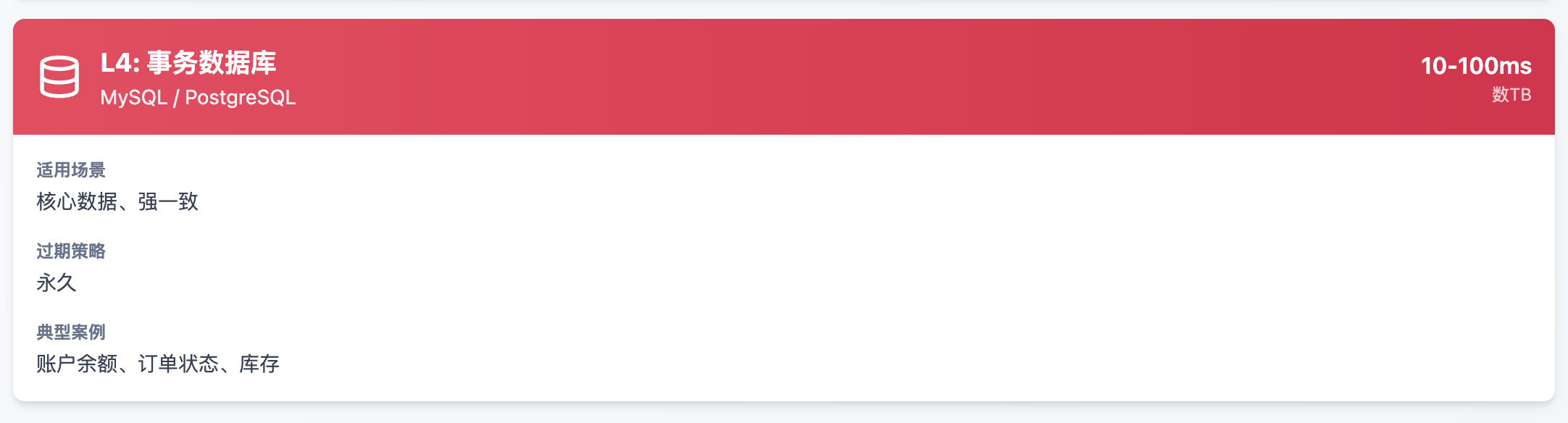
L4: 事务数据库
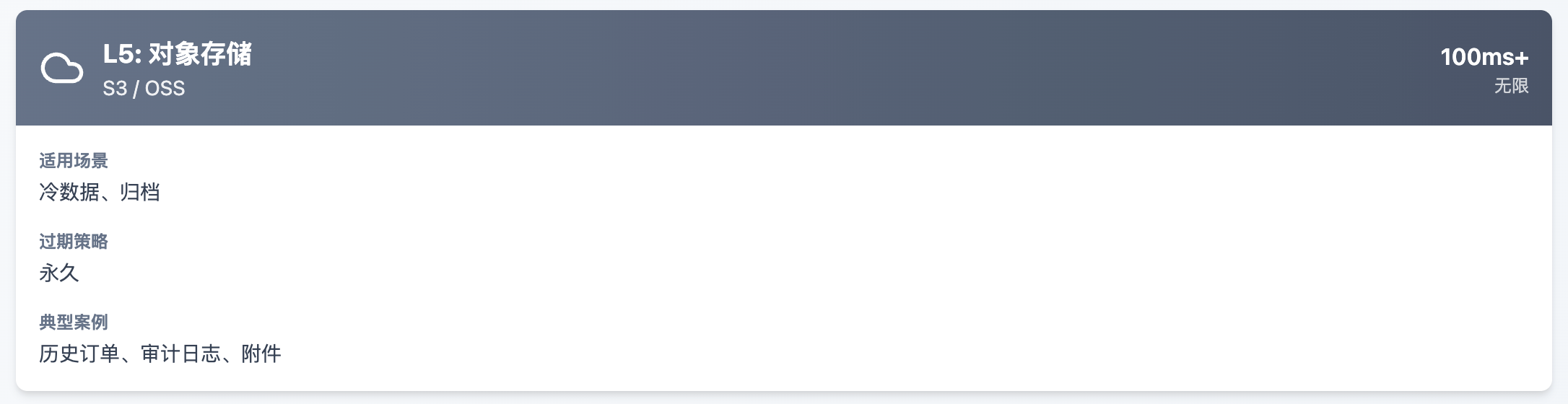
L5: 对象存储
实战案例:电商秒杀系统的分层策略
L1进程缓存: 秒杀商品的基础信息(名称、图片URL)在应用启动时加载到本地缓存, 避免每次请求都访问Redis。这样可以将单机QPS从5万提升到10万以上。
L2分布式缓存: 库存数量存储在Redis中,使用Lua脚本保证原子性扣减。 预热阶段将库存从MySQL同步到Redis,秒杀期间所有库存操作只打Redis,扛住每秒10万次扣减请求。
L3非事务存储: 秒杀订单先写入MongoDB,因为不需要立即保证ACID。 MongoDB的写入TPS可达10万+,远超MySQL的5000。
L4事务数据库: 通过MQ异步将订单从MongoDB同步到MySQL,处理支付、发货等强一致性流程。 高峰期可能延迟10-30秒,但业务可接受。
L5对象存储: 秒杀结束后,未支付订单和相关日志归档到OSS,节省数据库存储成本。
这个分层不是教条,而是根据真实业务演化出来的最佳实践。某社交平台的用户信息查询系统就是经典案例:
L1本地缓存存储登录用户自己的信息,命中率虽然只有20%但响应最快;
L2 Redis缓存存储活跃用户信息,覆盖80%的访问;
L3 MongoDB存储完整用户档案供运营分析;
L4 MySQL只保留核心账户数据。这套架构让他们用同样的硬件成本,将用户量从百万扩展到千万级别。
定位瓶颈:数据驱动的决策
性能优化最大的陷阱是凭直觉行事。我曾见过一个团队花了三周时间优化Java代码的GC参数,最后发现真正的瓶颈是数据库连接池只配置了10个连接,在高并发下线程大量阻塞等待连接。这个案例告诉我们:测量比优化更重要。
瓶颈定位与优化策略决策树
不同访问模式需要完全不同的优化路径
读多写少
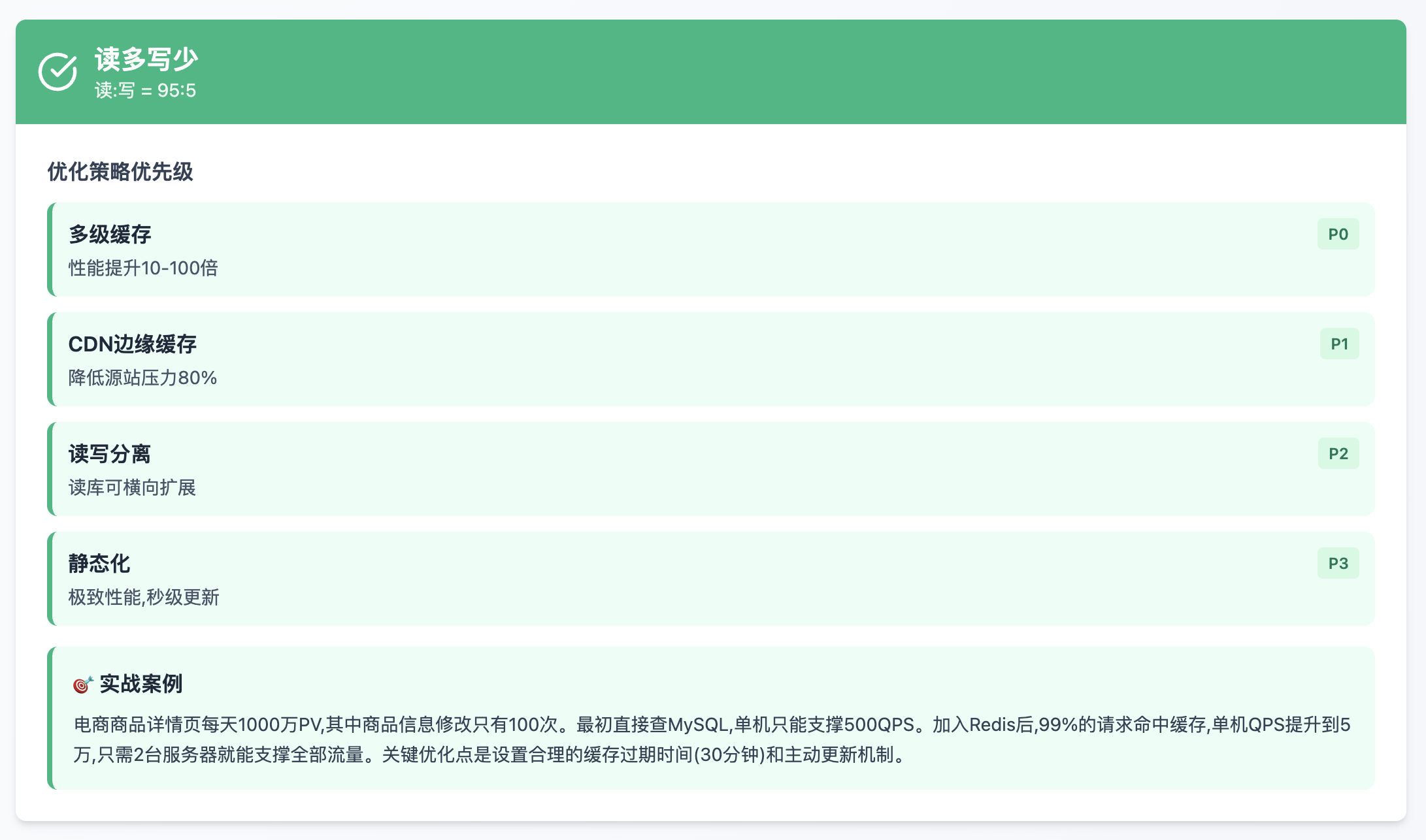
写多读少

读写均衡

突发流量

性能监控的黄金指标

真实案例:
某金融公司的交易系统在压测时发现P99延迟高达5秒,但P50只有50ms。通过APM工具追踪发现,问题出在偶发的full GC导致STW(Stop The World)。进一步分析发现是某个监控组件每分钟生成大量临时对象。禁用该监控后,P99延迟降到200ms。
这个案例说明:关注平均值会掩盖真实问题,P99/P999这种长尾指标才是用户真实体验。
实时性与一致性的权衡艺术
这是最考验架构师决策能力的地方。CAP定理不是理论,而是物理约束:在分布式系统中,一致性(Consistency)、可用性(Availability)、分区容错性(Partition tolerance)三者不可兼得。
一致性模型决策矩阵
性能、一致性、可用性的三角博弈
强一致性

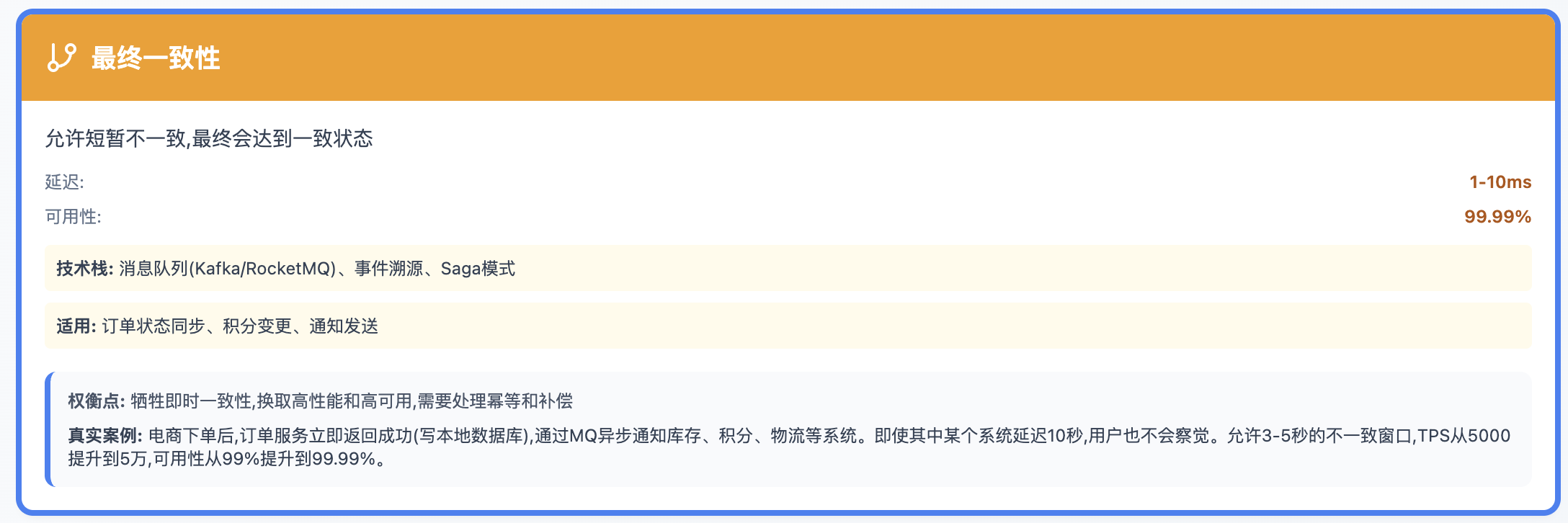
最终一致性
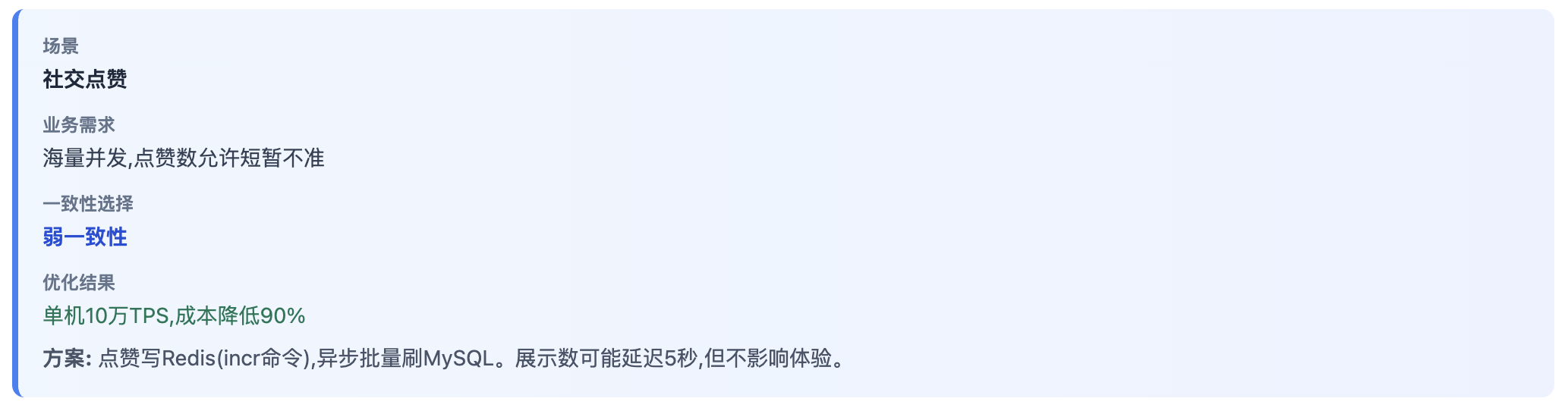
弱一致性

业务场景决策示例
电商秒杀

银行转账

社交点赞
决策框架:四个关键问题

某外卖平台的实践很有启发性:
用户下单时,订单写入MySQL(强一致),
骑手抢单写入Redis(最终一致),
配送轨迹写入MongoDB(弱一致)。
同一个系统的不同模块,根据业务特性选择不同的一致性级别,这才是真正的架构智慧。
微服务的真相与误区
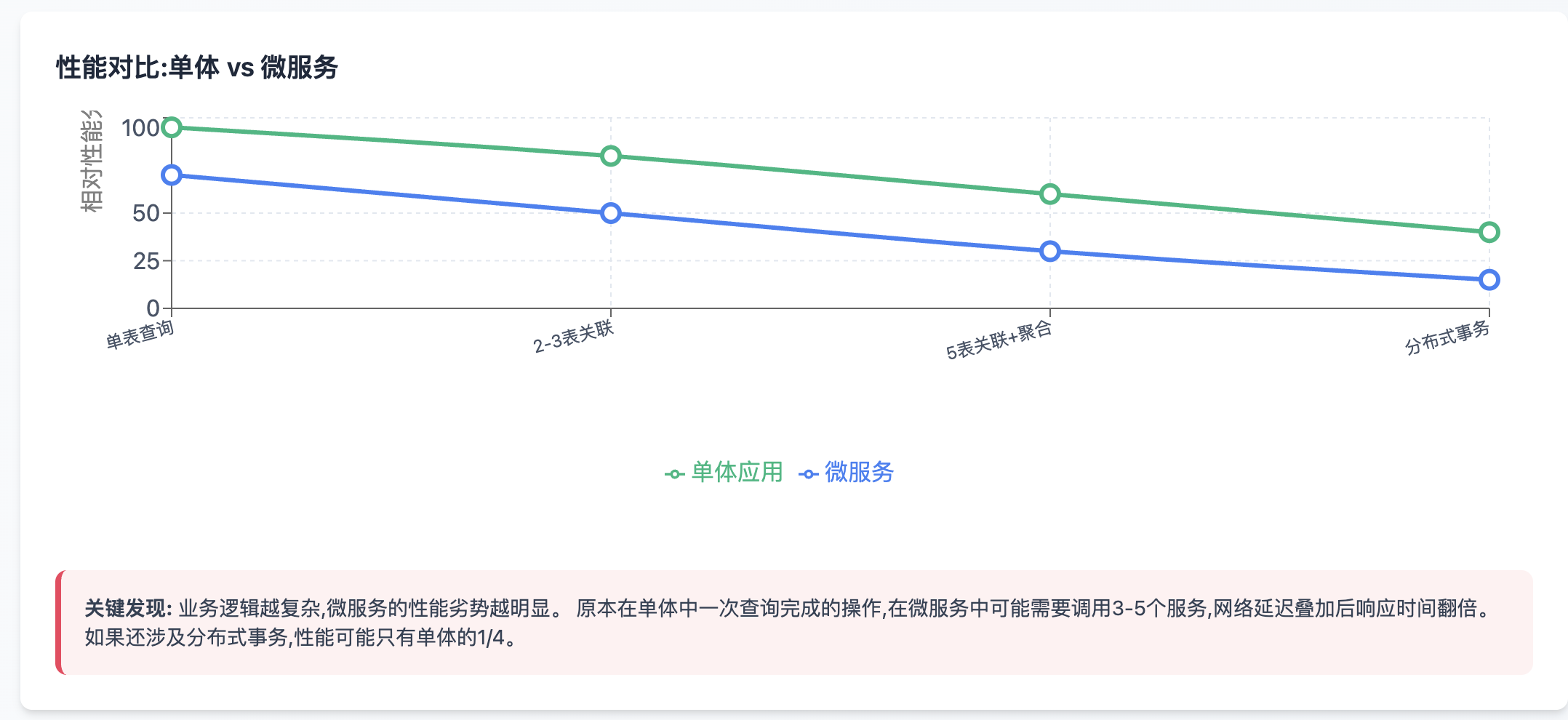
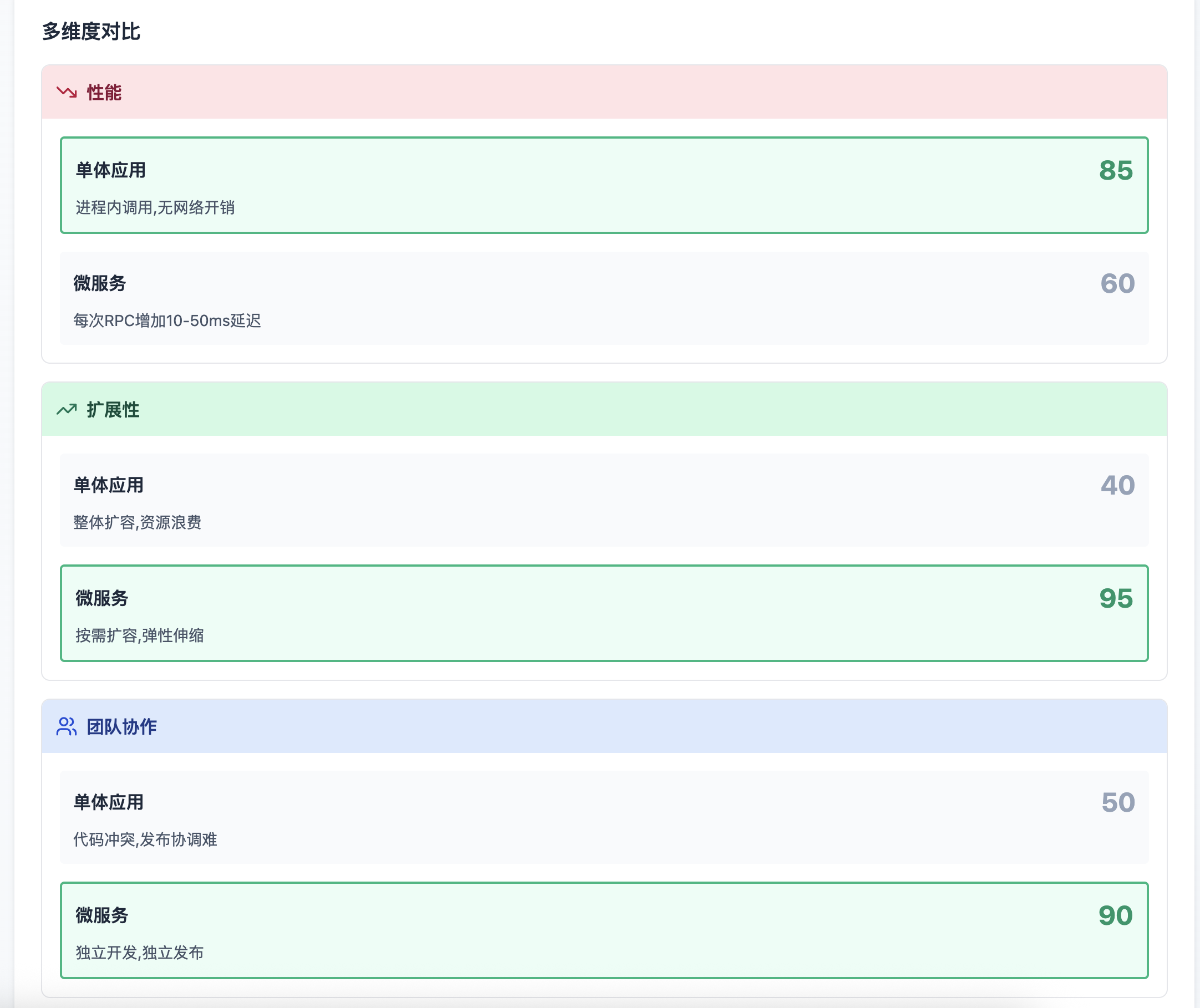
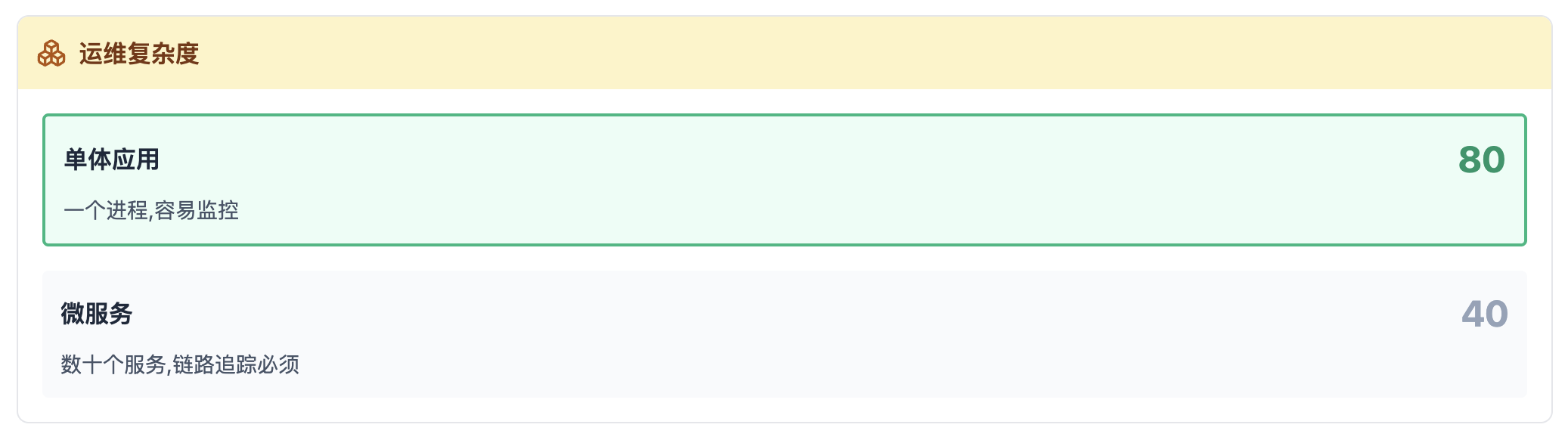
很多团队以为把单体应用拆成微服务就能提升性能,这是个危险的误解。让我用数据说话:
微服务的真相:工程优化 vs 性能代价
不要为了微服务而微服务,而要为了解决具体问题
性能对比:单体 vs 微服务
多维度对比
运维复杂度
真实演进案例

微服务决策清单

架构师的权衡决策框架
经过这么多年的实践,我总结出一套决策框架,希望能帮助你在面对复杂场景时做出更合理的选择:
第一步:明确约束条件
业务量级:当前QPS/TPS,未来6个月的增长预期
延迟要求:P50/P95/P99的目标值
一致性要求:强一致、最终一致、弱一致
预算限制:服务器成本、开发周期、团队能力
第二步:定位核心瓶颈
用监控工具(APM/链路追踪)找到最慢的环节
分析是CPU密集、IO密集还是网络密集
评估是读瓶颈还是写瓶颈
第三步:选择优化路径
读多写少 → 多级缓存 + CDN
写多读少 → 消息队列 + 批量写入
强一致性 → 分布式事务(TCC/Saga)
弱一致性 → 本地缓存 + 定时同步
第四步:小步快跑验证
灰度发布,从1%流量开始
监控关键指标,设置告警阈值
出现问题立即回滚,不要硬扛
优化是持续过程,没有一劳永逸
某视频网站的CDN优化就是典型案例:
最初视频文件存储在自建机房,全国用户访问延迟差异巨大,北京用户50ms,新疆用户500ms。
引入CDN后,将热门视频推送到边缘节点,全国延迟统一降到50ms以内,带宽成本降低70%,用户体验大幅提升。
这个优化不需要修改任何代码,只是把对的数据放到对的位置。
记住,过早优化是万恶之源,但完全不考虑性能也是不负责任的。最好的架构是能够随着业务演进而平滑演进的架构,而不是一次性设计出完美系统的幻想。
当你的系统从1万QPS增长到10万QPS,再到100万QPS,架构必然要随之调整。提前预留扩展点,避免重构时推倒重来,这才是架构师的核心价值。